
Commit44 //#JavaScript30 - Day 20 [Native Speech Recognition]
In this challenge we will use javascript to recognize native speech

I am learning with Skillcrush. Please check them out and consider signing up if you're looking to break into tech! Receive $250 off your course by using the link above. Use the coupon code: TWIXMIXY
NOTE: this discount is for Break Into Tech + Get Hired package exclusively. It's the same program I am participating in!
Today's challenge comes from JavaScript30.
I am exhausted today! I did some heavy lifting this week, so my muscles are working to recover and I’m trying to make sure I keep up my caloric intake to give my body what it needs to grow.
I have roller derby practice tonight and a webinar I want to attend about studying tips (something offered to students at Skillcrush), so let’s get into today’s challenge!
JavaScript30 - Day 20
Today is about speech recognition in the browser. Think talk to text.
Returning to coding everything into our HTML document, including style and script.
Here is the starter code:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Speech Detection</title>
<link rel="icon" href="https://fav.farm/🔥" />
</head>
<body>
<div class="words" contenteditable>
</div>
<script>
window.SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
</script>
<style>
html {
font-size: 10px;
}
body {
background: #ffc600;
font-family: 'helvetica neue';
font-weight: 200;
font-size: 20px;
}
.words {
max-width: 500px;
margin: 50px auto;
background: white;
border-radius: 5px;
box-shadow: 10px 10px 0 rgba(0,0,0,0.1);
padding: 1rem 2rem 1rem 5rem;
background: -webkit-gradient(linear, 0 0, 0 100%, from(#d9eaf3), color-stop(4%, #fff)) 0 4px;
background-size: 100% 3rem;
position: relative;
line-height: 3rem;
}
p {
margin: 0 0 3rem;
}
.words:before {
content: '';
position: absolute;
width: 4px;
top: 0;
left: 30px;
bottom: 0;
border: 1px solid;
border-color: transparent #efe4e4;
}
</style>
</body>
</html>We have that fun contenteditable attribute again. I imagine that’s so that our speech recognition functions will be able to type into that field, basically. But we will find out!
SpeechRecognition is a global variant that lives in the browser. And we are given a starter snippet to bring it into our window.
window.SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;To begin we need to create a new instance of speech recognition.
const recognition = new SpeechRecognition();
recognition.interimResults = true;So we create a new variable for the new speech recognition. This will allow us to see what we are saying, as we are speaking. Instead of waiting until we stop speaking.
Next we need to create a paragraph, where it will watch for gaps in speaking, to know when to create a new paragraph.
For this we will create our connections between script and style/UI.
let p = document.createElement('p');
const words = document.querySelector('.words');
words.appendChild(p);Now we need to listen for clicks?? I don’t understand that just yet.
Either way, we need to create a server for this one to run as well. So we’ll go to our project in terminal, run npm install, then npm start. I did something wrong with mine, so I’m going to have to try again. I think it’s because I did not have my file named index.html.
Yeah, can’t get it to work. So I’m going to see if I load it up in CodeSandbox if it’ll work.
NVM. I think I have it working for now. For whatever reason it’s taking me to the directly when it first boots up the server.

It does the same thing when I load it into CodeSandbox… so there’s no reason for me to work on it there if I’m having the same problem. BUT.. if I click on the index.html it takes me there, so hopefully I can keep working on it at the very least.

OK… now back to what we were doing.
We want to add an event listener, so we can listen for the results.
recognition.addEventListener('result', e => {
console.log(e);
})Then we wanted to console log the event, to see what’s happening… which is when we went down the server rabbit hole because we need the website to be live to do this.
We aren’t seeing anything, so we need to add recognition.start(); which will prompt the user to have access to their microphone when the page loads.
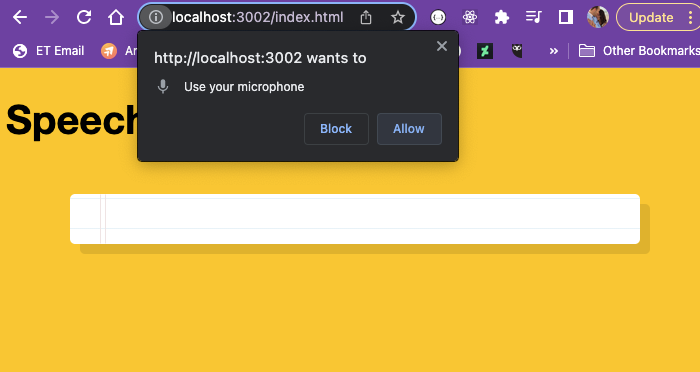
Sure enough there it is!
Now we can see information being logged in the console.

It is very nested, but if we dig down to the results, we can see words being captured.

All together it heard “hi my name is Janet” and you can also see the confidence. It is less confidence in correctly getting my name right.
Here is all of my script code so far:
<script>
window.SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
const recognition = new SpeechRecognition();
recognition.interimResults = true;
recognition.lang = 'en-US';
let p = document.createElement('p');
const words = document.querySelector('.words');
words.appendChild(p);
recognition.addEventListener('result', e => {
console.log(e.results);
})
recognition.start();
</script>Next we need to take the mess of nested logs and place them into a string together.
The cue to look for here is the isFinal property, so that the transcript recognition knows that I’m done speaking.

You can see in the final log it has placed the whole statement together, it’s 98% confident that it’s right and it says isFinal: true.
So we’re doing a couple things here. We want to see the transcription as it’s being taken, but then we want the sentence or the paragraph to modify and say the final statement once it is final.
This means we will need to map over the results array(we turn the string into an array).
We are expanding on this in our recognition event listener.
recognition.addEventListener('result', e => {
// console.log(e.results);
const transcript = Array.from(e.results)
.map(result => result[0])
console.log(transcript);
})
I like seeing how the confidence level goes up.
When we add .map(result => result.transcript) to the event listener then it will print what we’re saying in an array.

Now we need to take the pieces of the array and join them together.
recognition.addEventListener('result', e => {
const transcript = Array.from(e.results)
.map(result => result[0])
.map(result => result.transcript)
.join('')
console.log(transcript);
});
At this point if we stop speaking and start speaking again, it doesn’t work. So we need to create another event listener to handle that.
recognition.addEventListener('end', recognition.start);So this is listening for an end, and then when it should start recognition again.

We’re getting close to being able to output this in the UI!
p.textContent = transcript;This begins to place it in the UI, but every time we stop talking and start talking again it just overwrites what’s displaying.

So we need to write it so that IF the result is final, then it needs to create a new p element.
if(e.results[0].isFinal) {
p = document.createElement('p');
words.appendChild(p);
}
Awesome!!
Here is the entire script:
<script>
window.SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
const recognition = new SpeechRecognition();
recognition.interimResults = true;
recognition.lang = 'en-US';
let p = document.createElement('p');
const words = document.querySelector('.words');
words.appendChild(p);
recognition.addEventListener('result', e => {
// console.log(e.results);
const transcript = Array.from(e.results)
.map(result => result[0])
.map(result => result.transcript)
.join('')
p.textContent = transcript;
if(e.results[0].isFinal) {
p = document.createElement('p');
words.appendChild(p);
}
// console.log(transcript);
});
recognition.addEventListener('end', recognition.start);
recognition.start();
</script>See the live project on CodeSandbox!
You will need to grant access to your microphone for it to work.
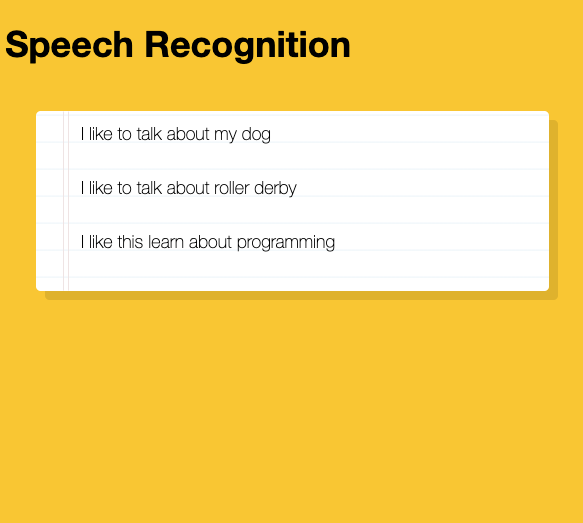
Thanks for joining me on today’s challenge. If you have any thoughts or feedback I’d love to hear from you. <3